

一文详解Python中哈希表的使用哈希娱乐
哈希游戏作为一种新兴的区块链应用,它巧妙地结合了加密技术与娱乐,为玩家提供了全新的体验。万达哈希平台凭借其独特的彩票玩法和创新的哈希算法,公平公正-方便快捷!万达哈希,哈希游戏平台,哈希娱乐,哈希游戏哈希表属于抽象数据结构,需要开发者按哈希表数据结构的存储要求进行API定制,对于大部分高级语言而言,都会提供已经实现好的、可直接使用的API,如JAVA中有MAP集合、C++中的MAP容器,Python中的字典
使用者可以使用API中的方法完成对哈希表的增、删、改、查一系列操作。
使用者角度:只需要知道哈希表是基于键、值对存储的解决方案,另需要熟悉不同计算机语言提供的基于哈希表数据结构的API实现,学会使用API中的方法。
开发者的角度:则需要知道哈希表底层实现原理,以及实现过程中需要解决的各种问题。本文将站在开发者的角度,带着大家一起探究哈希的世界。
大家都知道,基于列表(数组)的查询速度非常快,时间复杂度是O(1),常量级别的。
列表的底层存储结构是连续的内存区域,只要给定数据在列表(数组)中的位置,就能直接查询到数据。理论上是这么回事,但在实际操作过程,查询数据的时间复杂度却不一定是常量级别的。
如存储下面的学生信息,学生信息包括学生的姓名和学号。在存储学生数据时,如果把学号为0的学生存储在列表0位置,学号为1的学生存储在列表1位置

这里把学生的学号和列表的索引号进行关联,查询某一个学生时,知道了学生的学号也就知道了学生数据存储在列表中的位置,可以认为查询的时间复杂度为O(1)。
之所以可以达到常量级,是因为这里有信息关联(学生学号关联到数据的存储位置)。
但是,不是存储任何数据时,都可以找到与列表位置相关联的信息。比如存储所有的英文单词,不可能为每一个英文单词编号,即使编号了,编号在这里也仅仅是流水号,没有数据含义的数据对于使用者来讲是不友好,谁也无法记住哪个英文单词对应哪个编号。
所以使用列表存储英文单词后需要询时,因没有单词的存储位置。还是需要使用如线性、二分之类的查询算法,这时的时间复杂度由使用的查询算法的时间复杂度决定。
如果对上述存储在列表的学生信息进行了插入、删除等操作,改变了数据原来的位置后,因破坏了学号与位置关联信息,再查询时也只能使用其它查询算法,不可能达到常量级。
通过上述的分析,可以得出一个结论,要提高查询的速度,得想办法把数据与位置进行关联。而哈希表的核心思想便是如此。
哈希表引入了关键字概念,关键字可以认为是数据的别名。如上表,可以给每一个学生起一个别名,这个就是关键字。
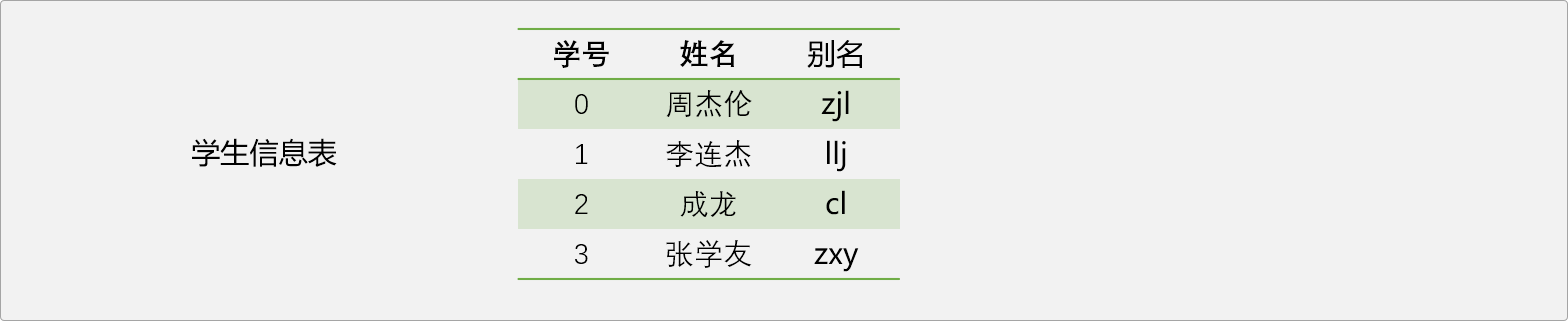
Tip:这里的关键字是姓名的拼音缩写,关键字和数据的关联性较强,方便记忆和查询。
有了关键字后,再把关键字映射成列表中的一个有效位置,映射方法就是哈希表中最重要的概念哈希函数。
哈希函数的功能:提供把关键字映射到列表中的位置算法,是哈希表存储数据的核心所在。如下图,演示数据、哈希函数、哈希表之间的关系,可以说哈希函数是数据进入哈希表的入口。

当需要查询学生数据时,同样需要调用哈希函数对关键字进行换算,计算出数据在列表中的位置后就能很容易查询到数据。
如果忽视哈希函数的时间复杂度,基于哈希表的数据存储和查询时间复杂度是O(1)。
哈希算法决定了数据的最终存储位置,不同的哈希算法设计方案,也关乎哈希表的整体性能,所以,哈希算法就变得的尤为重要。
Tip:无论使用何种哈希算法,都有一个根本,哈希后的结果一定是一个数字,表示列表(哈希表)中的一个有效位置。也称为哈希值。
使用哈希表存储数据时,关键字可以是数字类型也可以是非数字类型,其实,关键字可以是任何一种类型。这里先讨论当关键字为非数字类型时设计哈希算法的基本思路。
这里可以简单地把拼音看成英文中的字母,先分别计算每一个字母在字母表中的位置,然后相加,得到的一个数字。
前文说过哈希值是表示数据在列表中的存储位置,现在假设一种理想化状态,学生的姓名都是3个汉字,意味着关键字也是3个字母,采用上面的的哈希算法,最大的哈希值应该是zzz=26+26+26=78,意味着至少应该提供一个长度为78的列表 。
如果,现在仅仅只保存4名学生,虽然只有4名学生,因无法保证学生的关键字不出现zzz,所以列表长度还是需要78。如下图所示。
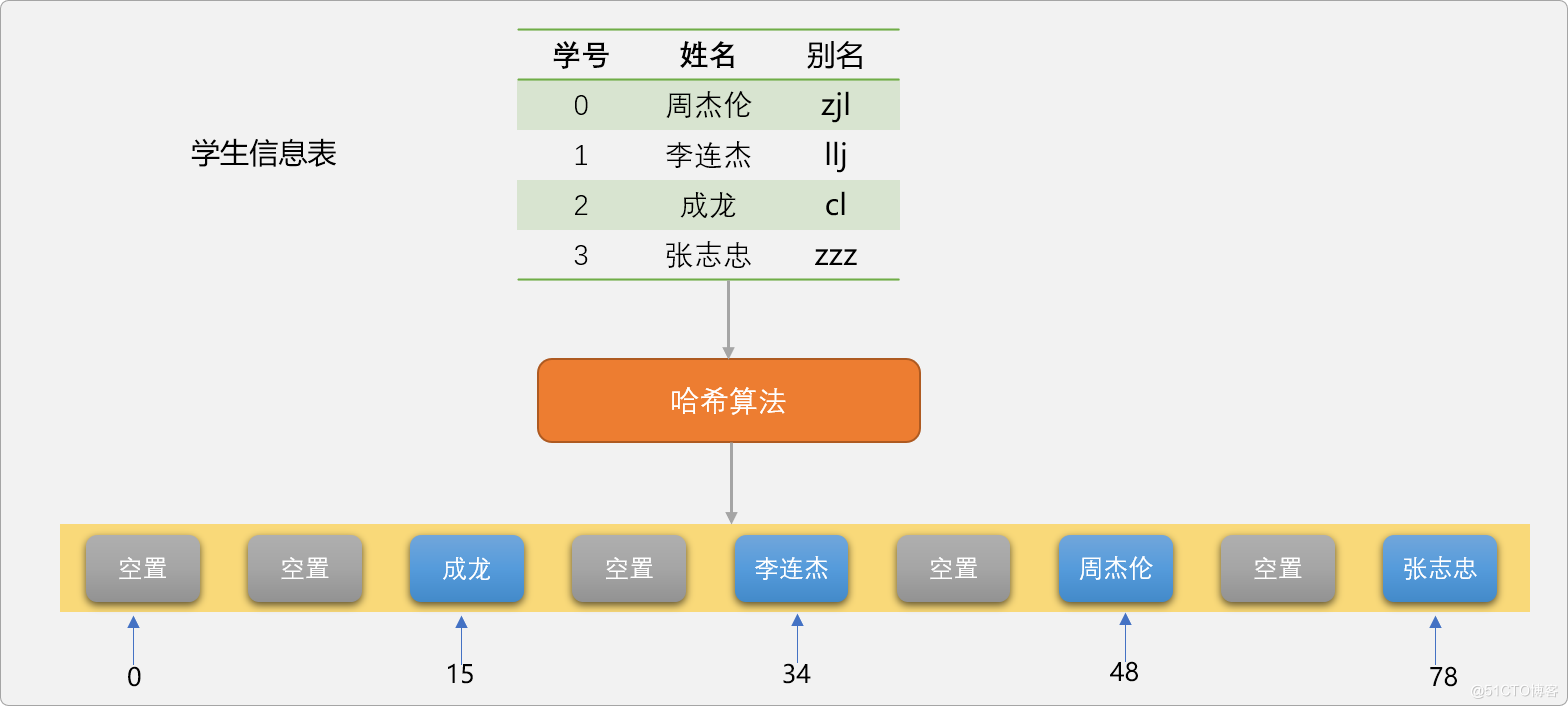
采用这种哈希算法会导致列表的空间浪费严重,最直观想法是对哈希值再做约束,如除以4再取余数,把哈希值限制在4之内,4个数据对应4个哈希值。我们称这种取余数方案为取余数算法。
取余数法中,被除数一般选择小于哈希表长度的素数。本文介绍其它哈希算法时,也会使用取余数法对哈希值进行适当范围的收缩。

4个存储位置存储4学生,应该是刚刚好,但是,只存储了3名学生。且还有1个位置是空闲的。现在编码验证一下,看是不是人为因素引起的。
这是因为李连杰和张志忠的哈希值都是2,导致在存储时,后面存储的数据会覆盖前面存储的数据,这就是哈希中的典型问题,哈希冲突问题。
所谓哈希冲突,指不同的关键字在进行哈希算法后得到相同的哈希值,这意味着,不同关键字所对应的数据会存储在同一个位置,这肯定会发生数据丢失,所以需要提供算法,解决冲突问题。
Tip:研究哈希表,归根结底,是研究如何计算哈希值以及如何解决哈希值冲突的问题。
针对上面的问题,有一种想当然的冲突解决方案,扩展列表的存储长度,如把列表扩展到长度为8。

貌似解决了冲突问题,其实不然,当试着设置列表的长度为6、7、8、9、10时,只有当长度为8时没有发生冲突,这还是在要存储的数据是已知情况下的尝试。
如果数据是动态变化的,显然这种扩展长度的方案绝对不是本质解决冲突的方案。即不能解决冲突,且产生大量空间浪费。
现实情况是,同时满足这2个条件的哈希算法几乎是不可能有的,面对数据量较多时,哈希冲突是常态。所以,只能是尽可能满足。
因冲突的存在,即使为100个数据提供100个有效存储空间,还是会有空间闲置。这里把实际使用空间和列表提供的有效空间相除,得到的结果,称之为哈希表的占有率(载荷因子)。
如上述,当列表长度为4时, 占有率为3/4=0.75,当列表长度为8时,占有率为4/8=0.5,一般要求占率控制 在0.6~0.9之间。
前面在介绍什么是哈希算法时,提到了取余数法,除此之外,还有几种常见的哈希算法。
折叠法:将关键字分割成位数相同的几个部分(最后一部分的位数可以不同)然后取这几部分的叠加和(舍去进位)作为哈希值。
因有相加求和计算,折叠法适合数字类型或能转换成数字类型的关键字。假设现在有很多商品订单信息,为了简化问题,订单只包括订单编号和订单金额。
第一步:把订单编号20201011按每3位一组分割,分割后的结果:202、010、11。
第二步:把分割后的数字相加202+010+11,得到结果:223。再使用取余数法,如果哈希表的长度为10,则除以10后的余数为3。
如订单编号19981112按3位一组分割,分割后的结果:199、811、12,间界叠加操作求和表达式为199+118+12=339,再把结果339%10=9。
求平方再取中算法,是一种较常见的哈希算法,从数学公式可知,求平方后得到的中间几位数字与关键字的每一位都有关,取中法能让最后计算出来的哈希值更均匀。
因要对关键字求平方,关键字只能是数字或能转换成数字的类型,至于关键字本身的大小范围限制,要根据使用的计算机语言灵活设置。
如下面的图书数据,图书包括图书编号和图书名称。现在需要使用哈希表保存图书信息,以图书编号为关键字,图书名称为值。
第二步:取3364的中间值36,然后再使用取余数方案。如果哈希表的长度为10,则36%10=6。
上述求平方取中间值的算法仅针对于本文提供的图书数据,如果需要算法具有通用性,则需要根据实际情况修改。
直接地址法:提供一个与关键字相关联的线性函数。如针对上述图书数据,可以提供线的选择会影响最终生成的哈希值的大小。可以根据哈希表的大小和操作的数据含义自行选择。
key为图书编号。当关键字不相同时,使用线性函数得到的值也是唯一的,所以,不会产生哈希冲突,但是会要求哈希表的存储长度比实际数据要大。
实际应用时,具体选择何种哈希算法,完全由开发者定夺,哈希算法的选择没有固定模式可循,虽然上面介绍了几种算法,只是提供一种算法思路。
当发生哈希冲突后,会在冲突位置之后寻找一个可用的空位置。如下图所示,使用取余数哈希算法,保存数据到哈希表中。

为删除状态,一定要标注此位置曾经保存过数据,而不能设置为空状态。为什么?如果设置为空状态,则在查询数字
为了保证当哈希值发生冲突后,如果从冲突位置查到哈希表的结束位置还是没有找到空位置,则再从哈希表的起始位置,也就是0位置再搜索到冲突位置。冲突位置是起点也是终点,构建一个查找逻辑环,以保证一定能找到空位置。
的方式跳跃式向前查找。目的是让数据分布均匀,减小数据聚集。除了采用增量探测之外,还可以使用再哈希的方案。也就是提供
个哈希函数,第1次哈希值发生冲突后,再调用第2个哈希函数再哈希,直到冲突不再产生。这种方案会增加计算时间。
这种方案的优势是不会产生额外的存储空间,但易产生数据聚集,会让数据的存储不均衡,并且会违背初衷,通过关键字计算出来的哈希值并不能准确描述数据正确位置。
链表法应该是所有解决哈希冲突中较完美的方案。所谓链表法,指当发生哈希冲突后,以冲突位置为首结点构建一条链表,以链表方式保存所有发生冲突的数据。如下图所示:

链表方案解决冲突,无论在存储、查询、删除时都不会影响其它数据位置的独立性和唯一性,且因链表的操作速度较快,对于哈希表的整体性能都有较好改善。
使用链表法时,哈希表中保存的是链表的首结点。首结点可以保存数据也可以不保存数据。
编码实现链表法:链表实现需要定义 2 个类,1 个是结点类,1 个是哈希类。
研究哈希表,着重点就是搞清楚哈希算法以及如何解决哈希冲突。在算法的世界时,没有固定的模式,开发者可以根据自己的需要自行设计哈希算法。
以上就是一文详解Python中哈希表的使用的详细内容,更多关于Python哈希表的资料请关注脚本之家其它相关文章!