

阿里巴巴写进Java开发哈希娱乐手册里推荐的JUC工具类:LongAdder确定不点进来学一下嘛?
哈希游戏作为一种新兴的区块链应用,它巧妙地结合了加密技术与娱乐,为玩家提供了全新的体验。万达哈希平台凭借其独特的彩票玩法和创新的哈希算法,公平公正-方便快捷!万达哈希,哈希游戏平台,哈希娱乐,哈希游戏昨天又从朋友那里倒腾过来一个好的题材:“JUC中的高性能计数器工具类LongAdder”。初步在网上搜索之后,发现其实阿里巴巴的Java开发手册中也有对于这个工具包的推荐:
JUC包下的所有工具类我都很感兴趣,因此昨晚加急看完了源码,在感叹其设计精巧的同时也决定写这篇文章分享给大家。
在高并发的场景下如果有统计类的需求的话,一开始我们使用的计数器是AtomicLong。但是AtomicLong的性能会随着并发量的上升而急剧下降,让我在代码层面看一看为什么会这样。

上面这段代码的逻辑很简单:手动写了一个死循环比较期望值,如果持有值与期望值相等就进行交换。
坏就坏在这里了:AtomicLong做自增操作的时候使用CAS+自旋会导致大量的线程在这里频繁的比较失败和自旋,这在大并发量的背景下,对整体项目的性能更是迎头重击。

所以JDK1.8中引入了一个新的原子操作类来解决这个问题。而它就是我们今天要介绍的LongAdder类:
LongAdder的整体设计思想并不难。我们照着AtomicLong的缺陷推理就能推理出来。
前面我们说过:AtomicLong的性能瓶颈主要在于高并发环境下会有大量的线程进入“比较失败和自旋”的漩涡中。
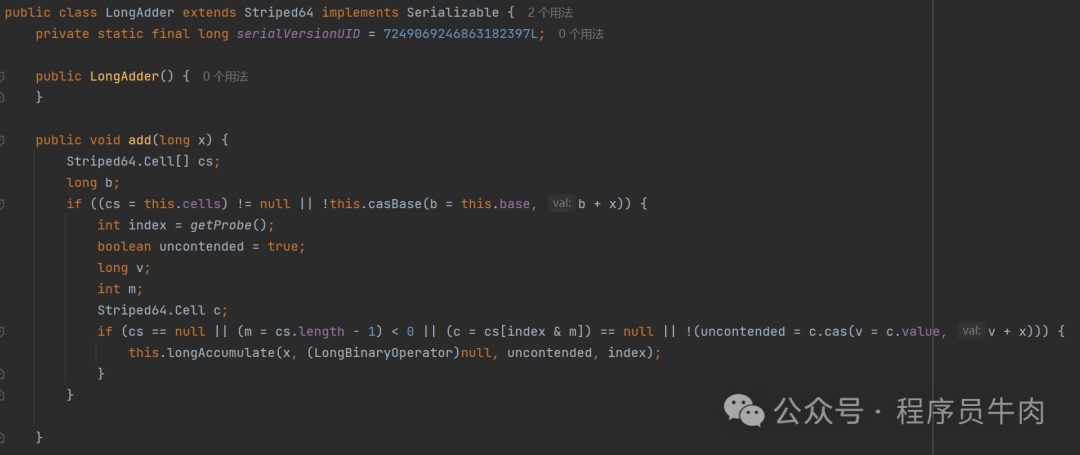
AtomicLong不是多个线程争夺一个value嘛?现在我们在LongAdder中就创建多个临时的value来供线程进行增值操作,而真正的value值等于这些临时value的值求和。
通过增加临时value的操作,我们大大减轻了高并发的场景下多线程在CAS操作中的竞争激烈度。
[LongAdder的基本思路就是分散热点,将value值的新增操作分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个value值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。]
我们可以尝试起一千个线程,每个线程都分别基于AtomicLong和LongAdder执行自增操作一万次。看一看AtomicLong和LongAdder的性能差距:
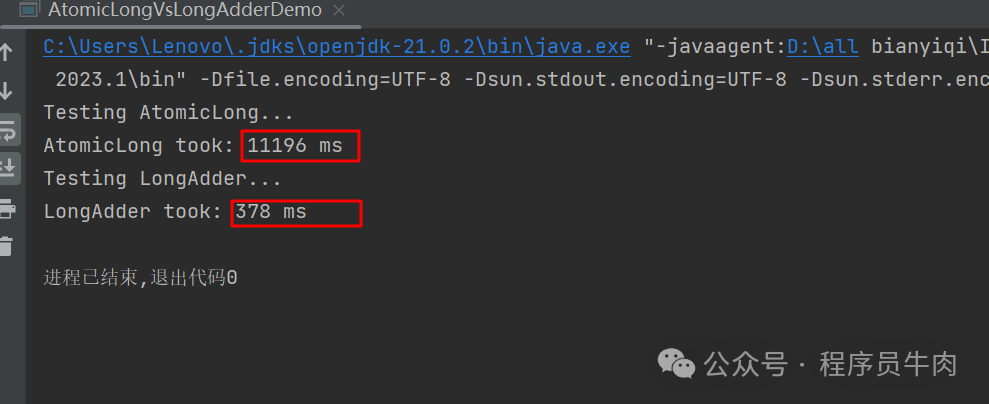
无需多言,这已经是单方面的羞辱了。现在知道LongAdder的性能有多高了吧?
如果你能理解我上面说的这些东西,那恭喜你已经掌握LongAdder的基本原理了,刷会抖音休息一下吧。
休息过后,让我们尝试来深入LongAdder的源码部分,学习其中精妙的设计思想。
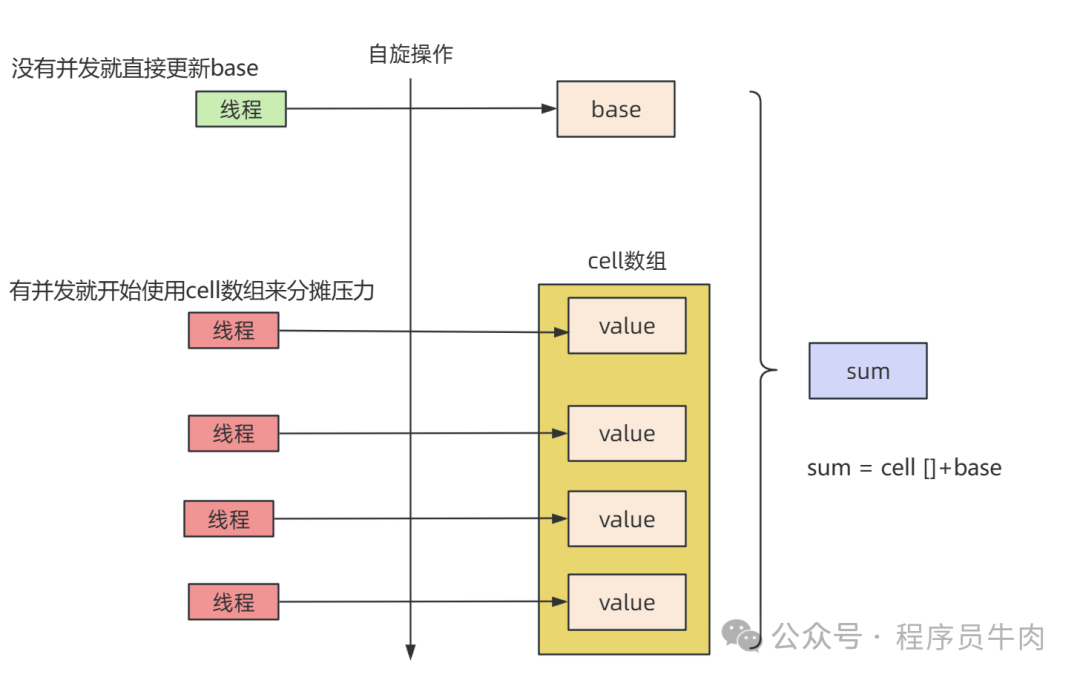
让我们来看看LongAdder中最重要的add方法,注释我一行行都写清了,这块一定要看:
//true-说明此时cell还未初始化。此时的背景是多线程写base的时候出现竞争了。
//false-说明此时cell已经初始化,现在线程应该根据前面分配的index往cell数组中的指定位置写值
//1.true-说明此时cell还未初始化。此时的背景是多线程写base的时候出现竞争了。
如果更新失败(或cells数组已存在),则获取一个随机索引,并尝试更新对应Cell的值。
如果Cell未初始化、为空或更新失败(存在竞争或者cell数组在扩容),则调用longAccumulate方法处理更复杂的累加逻辑
如果更新失败(或cells数组已存在),则获取一个随机索引,并尝试更新对应Cell的值。
如果Cell未初始化、为空或更新失败(存在竞争或者cell数组在扩容),则调用longAccumulate方法处理更复杂的累加逻辑
让我们继续来看longAccumulate这个方法,先介绍一下传入的参数:
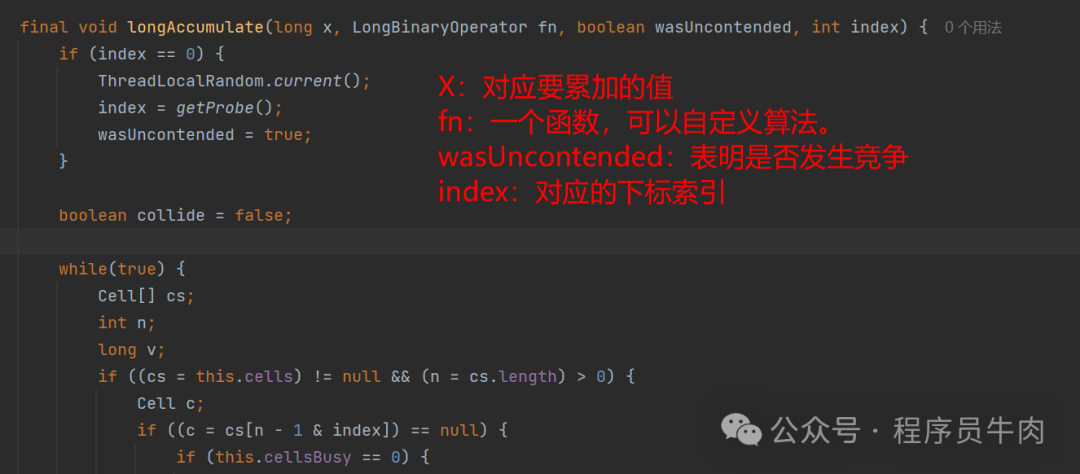
这里的逻辑是:如果index的位置为0(未分配位置),就给这个index重新取一个值。并且设置wasUncontended为“未竞争”。
这么做的意义是因为如果当前线程的hash值h=getProbe为0,0与任何数取模都是0,会固定到数组第一个位置,所有使用0作为初始index的线程都会尝试更新Cell数组的第一个位置,这会导致激烈的线程竞争。所以这里做了优化,使用ThreadLocalRandom为当前线程重新计算一个hash值。
最后设置wasUncontended = true,这里含义是重新计算了当前线程的hash后认为此次不算是一次竞争。hash值被重置就好比一个全新的线程一样,所以设置了竞争状态为true。
之后就开始进入逆天if循环了,首先在最外围写一个while死循环。实现“自旋”。
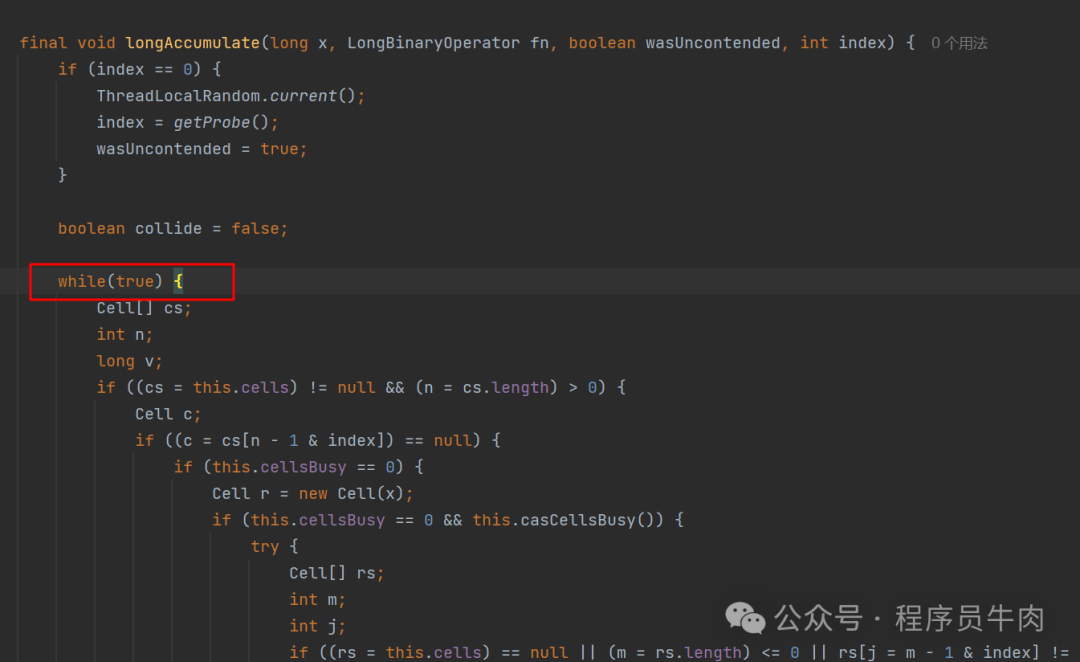
为了防止有些同学看懵逼,我们用文字串一下逻辑。在这一过程中,我们要明白:无论是多少层if嵌套循环,它本质上代表的还是一种情况而已。我们只要慢慢梳理就是可以梳理出来的。
情况一:cells数组已经初始化了,接下来的操作就是尝试把线程当前的值写到对应的cell中。
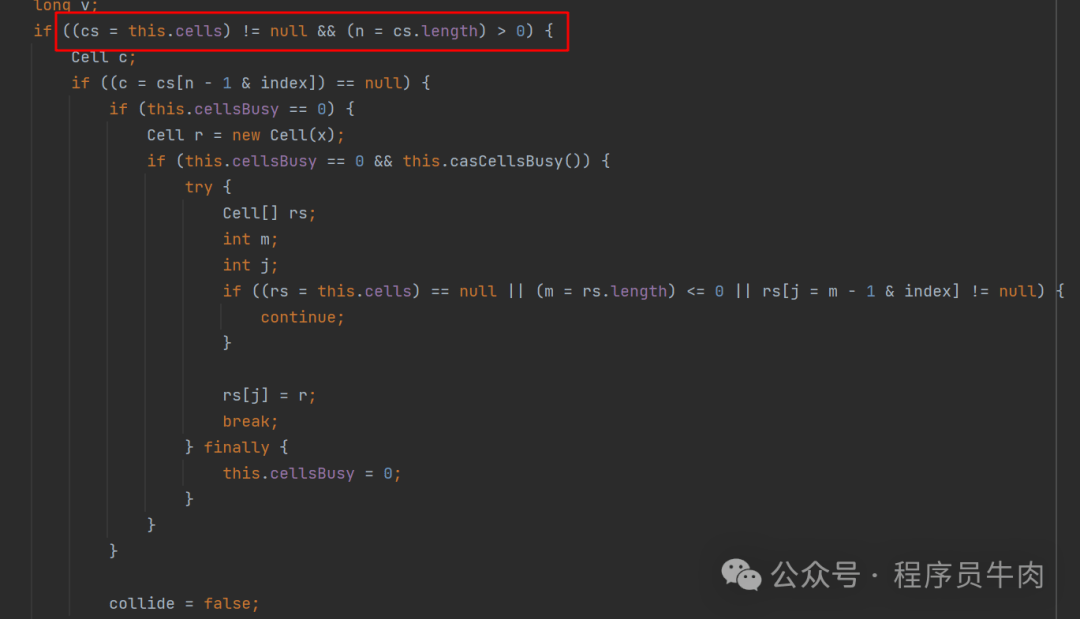
情况二:cell数组还没有初始化(所以情况1走不通),接下来的操作就是先持有锁,再去初始化cell数组。
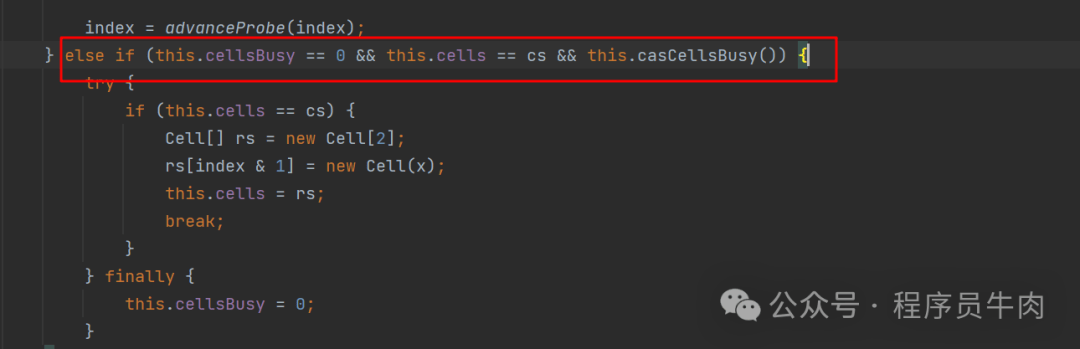
这个代码就很简单,我们可以看到我们创建了一个叫rs的cell对象。之后将[index&1]的位置赋值为一个初始值为x的cell对象。
[INDEX&1实际上是(index & (数组长度-1),只不过此时的数组长度是2,做完减一操作之后为1,直接写死在这里了。
我们可以把(index & (数组长度-1))看作是一个取余操作,思想和Hashmap中的设计一摸一样。这里不多作介绍]
情况三:走到这里说明当前的cell数组正在被初始化。因此它争取不到cellsBusy锁。开始尝试调用casBase操作来往base中写值。如果成功就结束本次循环。
情况1.1:cell数组虽然存在,但是内部对应的下标位置无cell。因此我们就要创建出来一个cell填充到cell数组中。
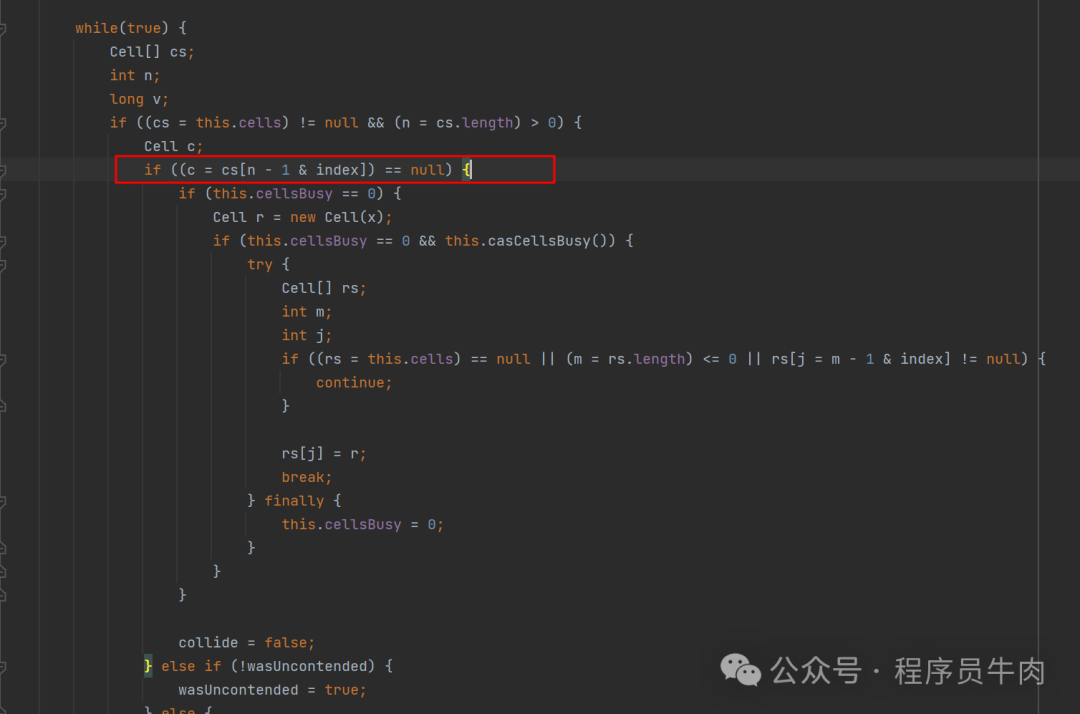
情况1.2:说明在走到1.1中的this.cellsBusy的时候获取锁失败。在这个我们要修改竞争条件为“有竞争”。
情况1.3:cell数组存在,而且对应的下标位置中cell也不为空。开始尝试给cell做加值操作。
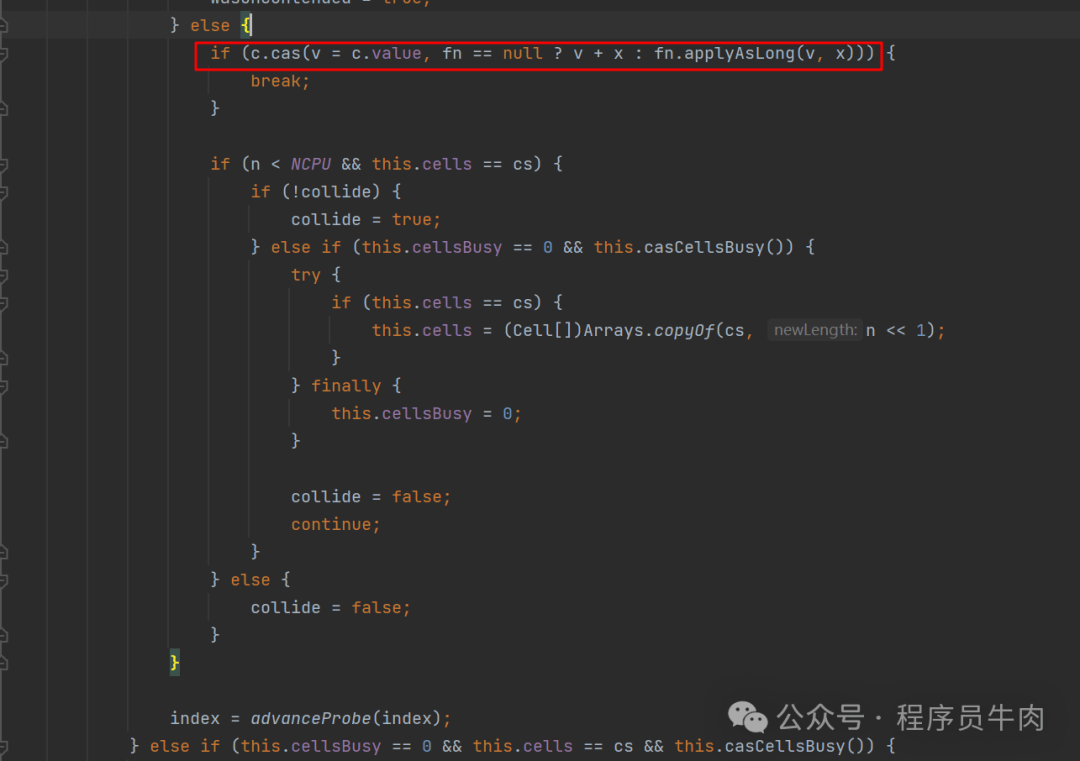
当累加完毕之后,开始走扩容操作。如果当前的cell数组长度小于当前电脑的CPU核心数并且cell的引用没有发生变化的话,就开始尝试扩容。
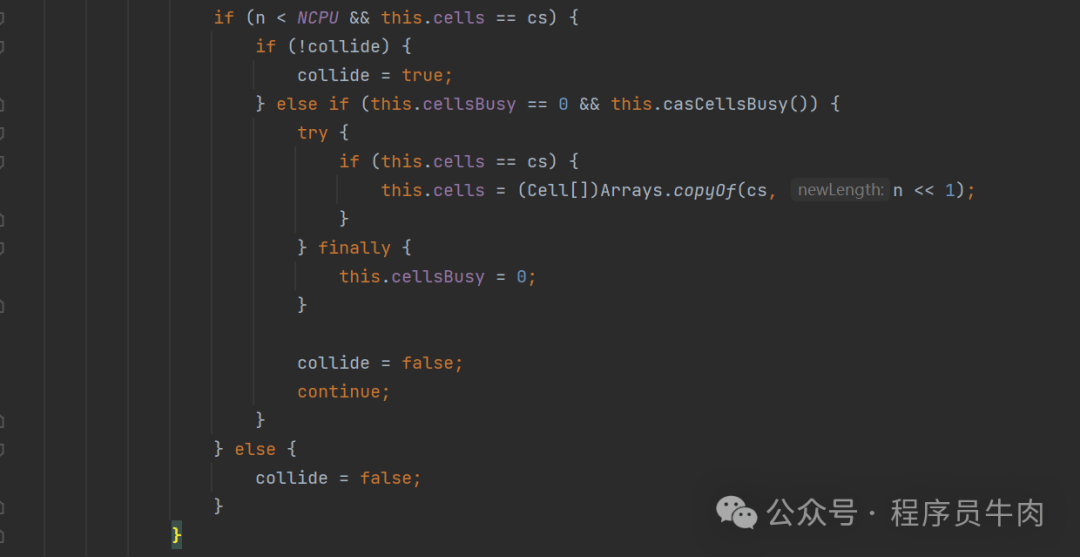
//case1:cell已经初始化了,当前线程就要把值写到对应的cell数组中
//再次判断锁是否被占用,如果没有被占用就使用casCellsBusy来获取锁
//如果cell数组的引用又发生变化或者cell数组rs对应的位置中不为空。说明已经有线程进行过更改了。为了避免覆盖旧值,我们放弃本次更改。
//case1.2: 只有可能出现在cell初始化之后,当前线程竞争修改失败才会是false。
//fasle-写新的cell的时候又存在竞争,开始走下一轮自旋
//case1.4: 如果cell数组长度小于Ncup并且当前线程持有的仍然是cs这个引用的话。(其他线程没有对cs进行扩容等操作)
//开始走真正的扩容,先去判断锁的情况(cellsBusy),如果没有线程持有锁的情况下,在使用casCellsBusy来持有锁
//case1.5: 由于当前的cell数组的长度已经超过当前电脑的CPU核心数了。因此不进行扩容。
// 由于当前线程持有的不再是cs这个cell数组了。说明已经有其他线程做了扩容操作,因此不再进行扩容
//再次判断,避免线程并发下的问题:两个线程都进行了初始化,导致丢数据的情况
// cell被其他线程初始化了。导致当前线程找不到对应的cell,当前线程需要把数据累加到base中。
基于这种操作,我们就实现了LongAdder中的“分摊竞争压力”。不得不说,这段代码真的是简洁高效且逻辑复杂。
一遍看不懂是正常的,我非常推荐你自己去看一看。下来我们看一看这个cell数组中的cell对象:
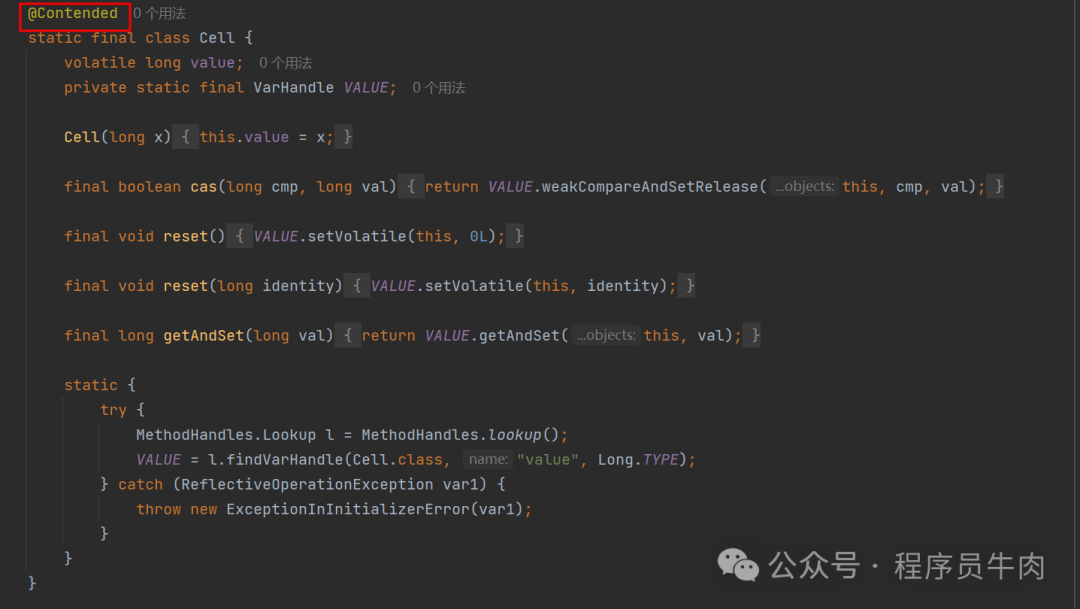
Cell注定要被多线程所共享,所以在这一过程中数组中的每一个cell对象都使用了@Contended注解来避免伪共享问题。
[伪共享是指多个线程访问不同的变量,但这些变量恰好位于同一个缓存行中。由于缓存行是共享的,当一个线程修改其中一个变量时,整个缓存行的状态会被标记为“脏”(dirty),其他线程必须重新加载整个缓存行,即使它们访问的是缓存行中的其他变量。这种不必要的缓存行刷新和重新加载会导致性能下降。]
在多线程环境中,线 调用incrementA,线 调用incrementB。a和b是两个独立的变量,但它们可能位于同一个缓存行中。当线 修改a时,整个缓存行会被标记为脏,线 也需要重新加载缓存行,尽管它只关心b。这就是伪共享问题。
最后我们再来看一看LongAdder中是如何对base和cells数组的值进行求和的:
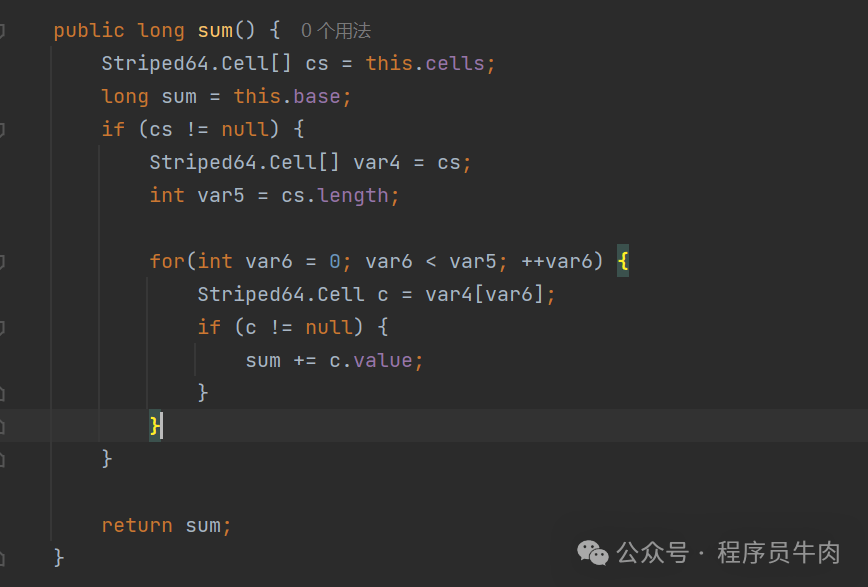
没啥好讲的,直接硬遍历了。需要注意的是这里的sum并不一保证能拿到精确值。
这是因为当多个线程同时更新LongAdder时,它们可能正在修改base值或者Cell数组中的值。由于这些更新操作是并发进行的,所以在调用sum方法时,可能有些更新尚未完成,从而导致返回的总和不是最新的精确值。
在读完这个类之后,其实越来越发现JUC的底层很多类的设计思想是共通的。LongAdder中所体现出来的“分治”的思想,其实就有点像“分段锁”。
那今天关于“LongAdder”的文章就介绍到这里了。相信通过我的介绍,你已经大致了解了LongAdder。希望我的文章可以帮到你。
关于JUC中的各种类,你有什么想分享的嘛?欢迎在评论区留言。返回搜狐,查看更多