

哈希娱乐还不清楚HashMap吗?读完这篇你就懂了!
哈希游戏作为一种新兴的区块链应用,它巧妙地结合了加密技术与娱乐,为玩家提供了全新的体验。万达哈希平台凭借其独特的彩票玩法和创新的哈希算法,公平公正-方便快捷!万达哈希,哈希游戏平台,哈希娱乐,哈希游戏HashMap对于使用Java的小伙伴们来说最熟悉不过,每天都在使用它。这次主要是分析下HashMap的工作原理,为什么我会拿这个东西出来分析,主要是最近面试的小伙伴们,中被人问起HashMap,HashMap涉及的知识远远不止put和get那么简单。
为什么叫做HashMap?内部是怎样实现的呢?使用的时候大多数都是用String作为它的key呢?下面就让我们来了解HashMap,并给你详细解释这些问题。
其实HashMap的由来是基于Hasing技术(Hasing),Hasing就是将很大的字符串或者任何对象转换成一个用来代表它们的很小的值,这些更短的值就可以很方便的用来方便索引、加快搜索。
HashMap是一个用于存储Key-Value键值对的集合,你可以用一个”key”去存储数据。当你想获得数据的时候,你可以通过”key”去得到数据,每一个键值对也叫做Entry。这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干。
HashMap作为一种数据结构,像数组和链表一样用于常规的增删改查,在存数据的时候(put)并不是随便乱放,而是会先进行一次分配索引(可以理解为“分类”)的操作再存储,一旦分配索引存储之后,下次取(get)的时候就可以大大缩短查找的时间。我们知道数组在执行查、改的效率很高,而增、删(不是尾部)的效率低,链表相反,HashMap则是把这两者结合起来,看下HashMap的数据结构
size,就是HashMap的存储大小。threshold是HashMap临界值,也叫阀值,如果HashMap到达了临界值,需要重新分配大小。loadFactor是负载因子, 默认为75%。阀值 = 当前数组长度✖负载因子。modCount指的是HashMap被修改或者删除的次数总数。
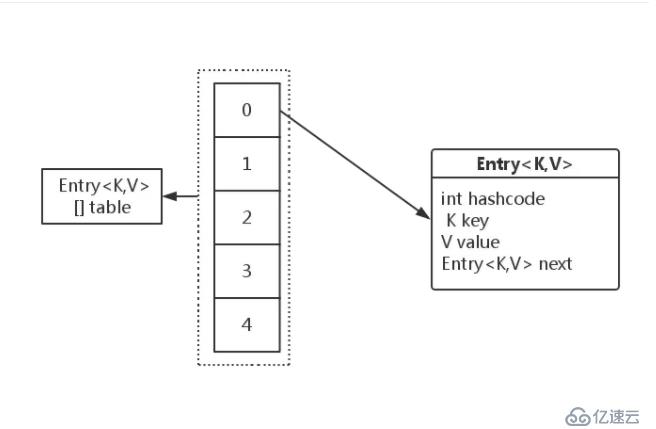
Entry分散存储在一个Entry类型的数组table, table里的每一个数据都是一个Entry对象。Y轴方向代表的就是数组,X轴方向就是链表的存储方式。
table里面存储的Entry类型,Entry类里包含了hashcode变量,key,value 和另外一个Entry对象。因为这是一个链表结构。通过我找到你,你再找到他。不过这里的Entry并不是LinkedList,它是单独为HashMap服务的一个内部单链表结构的类。
3、根据对应的索引找到对应的数组,就是找到了其所在的链表,然后按照链表的操作对Value进行插入、删除和查询操作。
hash 方法我们都知道在Java中每个对象都有一个hashcode()方法用来返回该对象的 hash值。HashMap先对hashCode进行hash操作,然后再通过hash值进一步计算下标。
HashMap是怎么通过Hash查找数组的索引的呢,调用indexFor,其中h是hash值,length是数组的长度,这个按位与的算法其实就是h%length求余。
其中h是hash值,length是数组的长度,这个按位与的算法其实就是h%length求余。
一般什么情况下利用该算法,典型的分组。例如怎么将100个数分组16组中,就是这个意思。应用非常广泛。
在做按位与的时候,始终是低位在做计算,高位不参与计算,因为高位都是0。这样导致的结果就是只要是低位是一样的,高位无论是什么,最后结果是一样的,如果这样依赖,hash碰撞始终在一个数组上,导致这个数组开始的链表无限长,那么在查询的时候就速度很慢,又怎么算得上高性能的啊。所以hashmap必须解决这样的问题,尽量让key尽可能均匀的分配到数组上去。避免造成Hash堆积。
调用put方法时,尽管我们设法避免碰撞以提高HashMap的性能,还是可能发生碰撞。据说碰撞率还挺高,平均加载率到10%时就会开始碰撞。
我们都知道在Java中每个对象都有一个hashcode()方法用来返回该对象的 hash值。HashMap先对hashCode进行hash操作,然后再通过hash值进一步计算下标。
由上面的代码可以看出,初始化的时候需要知道初始化的容量大小,因为在后面要通过按位与的Hash算法计算Entry数组的索引,那么要求Entry的数组长度是2的N次方。
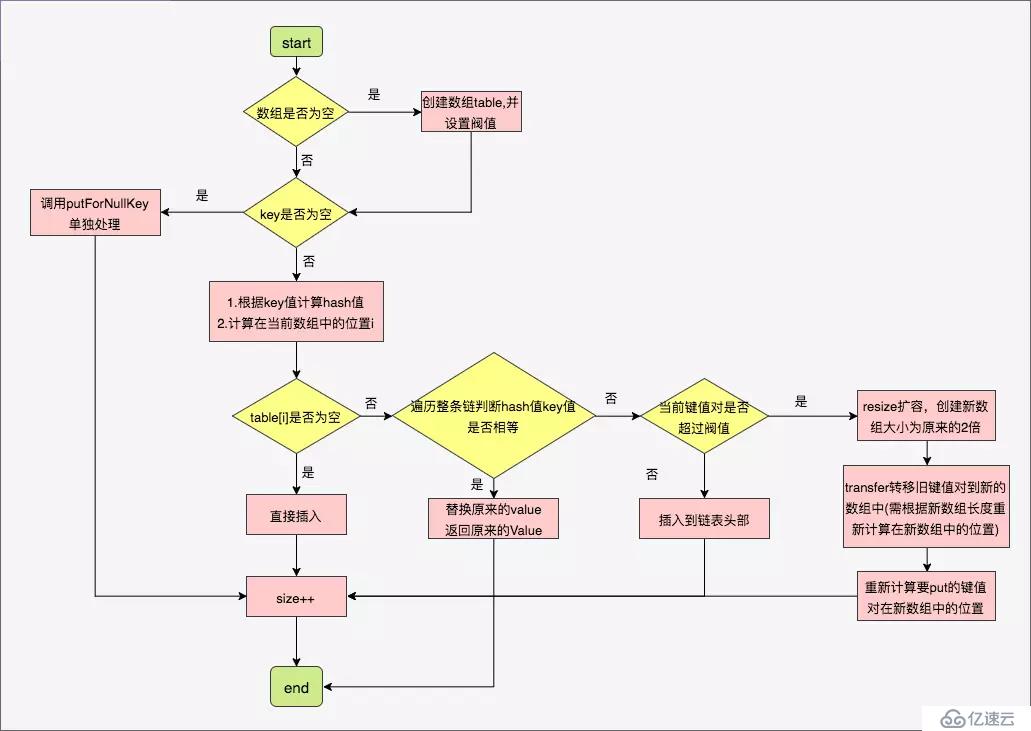
如果key为null的值,默认就存储到table[0]开头的链表了。然后遍历table[0]的链表的每个节点Entry,如果发现其中存在节点Entry的key为null,就替换新的value,然后返回旧的value,如果没发现key等于null的节点Entry,就增加新的节点。
(3) 然后遍历以table[i]为头节点的链表,如果发现有节点的hash,key都相同的节点时,就替换为新的value,然后返回旧的value。
如果没有找到key的hash相同的节点,就增加新的节点addEntry(),代码如下:
(4)如果HashMap大小超过临界值,就要重新设置大小,扩容,稍后讲解。
我们通过hashMap.get(K key) 来获取存入的值,key的取值很简单了。我们通过数组的index直接找到Entry,然后再遍历Entry,当hashcode和key都一样就是我们当初存入的值啦。
相比put,get操作就没这么多套路,只需要根据key值计算hash值,和数组长度取模,然后就可以找到在数组中的位置(key为空同样单独操作),接着就是Entry遍历,hash相等的情况下,如果key相等就知道了我们想要的值。
众所周知,HashMap不是线程安全的,但在某些容错能力较好的应用中,如果你不想仅仅因为1%的可能性而去承受hashTable的同步开销,HashMap使用了Fail-Fast机制来处理这个问题,你会发现modCount在源码中是这样声明的。
调用put方法时,当HashMap的大小超过临界值的时候,就需要扩充HashMap的容量了。代码如下:
如果大小超过最大容量就返回。否则就new 一个新的Entry数组,长度为旧的Entry数组长度的两倍。然后将旧的Entry[]复制到新的Entry[].代码如下:
到这里相信你对HashMap内部已经非常清楚了,如果本篇文章对你有帮助记得关注我,我会继续更新文章,感谢支持!